Retrieving Dialogue History in Deep Neural Networks for Spoken Language Understanding

Adv. Sci. Technol. Eng. Syst. J. 2(3), 1741–1747 (2017);
 DOI: 10.25046/aj0203213
DOI: 10.25046/aj0203213
In this paper, we propose a revised version of the semantic decoder for multi-label classification task in the spoken language understanding (SLU) pilot task of the Dialog State Tracking Challenge 5 (DSTC5). Our model concatenates two deep neural networks – a Convolutional Neural Network (CNN) and a Recurrent Neural Networks (RNN) – for detecting semantic meaning of incoming utterance with the assistance of algorithm adaptation method. In order to evaluate the robustness of our proposed models, comparative experiments on the DSTC5 dialogue datasets are conducted. Experimental results show that the proposed models outperform most of the submitted models in the DSTC5 in terms of F1-score. Without any manually designed features or delexicalization, our model has proven its efficiency of tackling the multi-label SLU task, using only publicly available pre-trained word vectors. Our model is capable of retrieving the dialogue history, and thereby it could build the concise concept structure by employing the pragmatic intention as well as semantic meaning of utterances. The architecture of our semantic decoder has a potential to be applicable to other variety of human-to-human dialogues to achieve SLU.
1. Introduction
The spoken language understanding (SLU) has been one of the fundamental components of an end-to-end dialogue system. The Dialog State Tracking Challenge 5 (DSTC5) released a pilot SLU task, which requires to extract semantic meaning of users’ utterances in task-oriented dialogues and to fill the slots with speech acts. Unlike the previous challenges (DSTC 2&3) where the human-to-system dialogues were targeted, the corpus of DSTC 5 has been no more than challengeable due to the following points: human-to-human dialogues, cross-linguistic data and multi-label classification task. As its corpus is built by collecting human-to-human conversation in a natural setting, more than one speech act can be annotated to a single utterance.
Xu et al. propose a Convolutional Neural Network (CNN) model with a threshold predictor to tackle a multi-label speech act classification task on DSTC5 corpus [1]. With the assistance of algorithm adaptation method, the model they propose is adapted for the multi-label classification task without any manually designed features. Although the model, however, has advantage of handling the multi-label classification task, there still remain rooms for improvement to achieve state-of-art SLU.
The aim of this study is to improve the model proposed by Xu et al. by building a more robust and concise semantic classifier. In this revised model two deep neural networks, Convolutional Neural Network and Recurrent Neural Network, are conjoined to conduct a multi-label speech act classification task in an improved fashion. Our newly revised model shows a synergy effect of retrieving dialog context as well as exploiting a current utterance. In addition, a threshold learning mechanism is engaged to enable our proposed model to produce an output of a set of multiple labels called speech acts.
The rest of this paper is organized as follows. Section 2 gives a brief review of DSTC5 dataset and some related works in the SLU pilot task. In Section 3, we introduce the architecture of our proposed model and a threshold predictor. The Section 4 gives a detailed description of the DSTC5 dataset and describes how we set up the experiments for training data and evaluation process. In Section 5, we provide our experimental results to optimize the
Table 1. An example of test utterances annotated with speech act information.
|
performance of our CNN-RNN classifier on the DSTC5 SLU task. The Section 6 discusses the differences between the previous and current models and the strength of concatenating two deep neural networks in SLU task. The Section 7 concludes this paper[1].
2. Background
2.1. The DSTC5 Dataset
The DSTC5 provides the TourSG corpus, which consists of dialogue sessions collected from Skype calls between tour guides and tourists focusing on offering touristic information of Singapore[2]. For the SLU task, the system is given the utterances from both the tourist and the guide as its input, and the system subsequently tags the utterances spoken by both the speakers with appropriate speech acts categories and attributes.
Each sub-utterance belongs to one of the four basic speech act categories that denote general information of current dialogue flow. More specific speech act information can be annotated by the combination with the speech act attributes. Therefore, a classifier is demanded for classifying a set of labels consisting of speech act categories and attributes tagged to a single utterance. Reference [3] gives complete list of speech act categories and attributes.
Table 1 shows Chinese test utterances and ones translated in English that annotated with their corresponding speech act categories and attributes.
2.2. Other models in pilot SLU task of the DSTC5
A simple baseline model for the SLU task is provided by the committee of the DSTC 5, which uses a binary relevance (BR) approach and trains a set of linear support vector machines (SVM) for multi-label speech act classification. The baseline model is built within traditional TF-IDF approach which mainly depends on keywords that appeared in the utterances per speaker. This baseline model, however, has a crucial deficiency in detecting semantic meanings of utterances appropriately, as it only superficially decodes meaning relying on words on the surface level.
Ushio et al., which takes the first place in this challenge, proposes a local co-activate multi-task learning model (LC-MTL) for capturing structured speech acts by using recurrent convolutional neural networks[4]. This model consists of a CNN, which represents incoming utterances as sentence vectors, and two LSTMs, which locally co-activates neurons in hidden layer between speech act categories and attributes of the corresponding utterances.
Xu et al also proposes a CNN model with a threshold predictor, which enables to predict more than one speech act annotated to an utterance. It has been proven that CNN is capable to detect the core semantic meaning without any knowledge on the syntactic structures of a language or any manually designed features. This model, however, has faced the ambiguity issue, as the output node of CNN only depend on each current utterance to produce proper scores for each set of labels. In Section 3 we will introduce the revised version of the semantic decoder that has a power to disambiguate the meaning of utterances.
2.3. Related Works
So far there have been many researches grounded on CNN architecture with regard to the language processing tasks. The CNN proposed by Kim achieves good performance across several datasets despite of its simple architecture which consists of a convolutional layer, a max-pooling layer and a softmax classifier. Wang et al. proposed another architecture of CNN with an additional semantic layer, which exploits the contextual information from short texts[6]. Another CNN model with an unsupervised “region embedding”, proposed by Johnson, works well for long text classification task like movie reviews[7]. Zhang et al. explored the effects of hyperparameters in one-layer CNN architectures, and reported their impact on performance over multiple runs[8].
In addition, recent advances in deep learning with RNN including LSTM have also achieved impressive improvements on various natural language processing tasks such as language modeling, sequence tagging and machine translation. Language model based on RNN(RNN-LM) was proposed by Mikolov et al., which significantly outperformed the previous back-off models, even in case when RNN-LM was trained on much less data than back-off models were [9]. Another variant of RNN-LM based on LSTM proposed by Sundermeyer, showed additional improvements of 8% relative in perplexity over the RNN-LM[10]. Huang et al. proposed a sequence tagging model using a bidirectional LSTM, which was capable of using effectively both previous and oncoming input features. Their model have achieved state of the art accuracy on various sequence tagging tasks such as POS tagging, chunking and named entity recognition(NER)[11]. Sutskever et al. proposed a sequence to sequence learning model
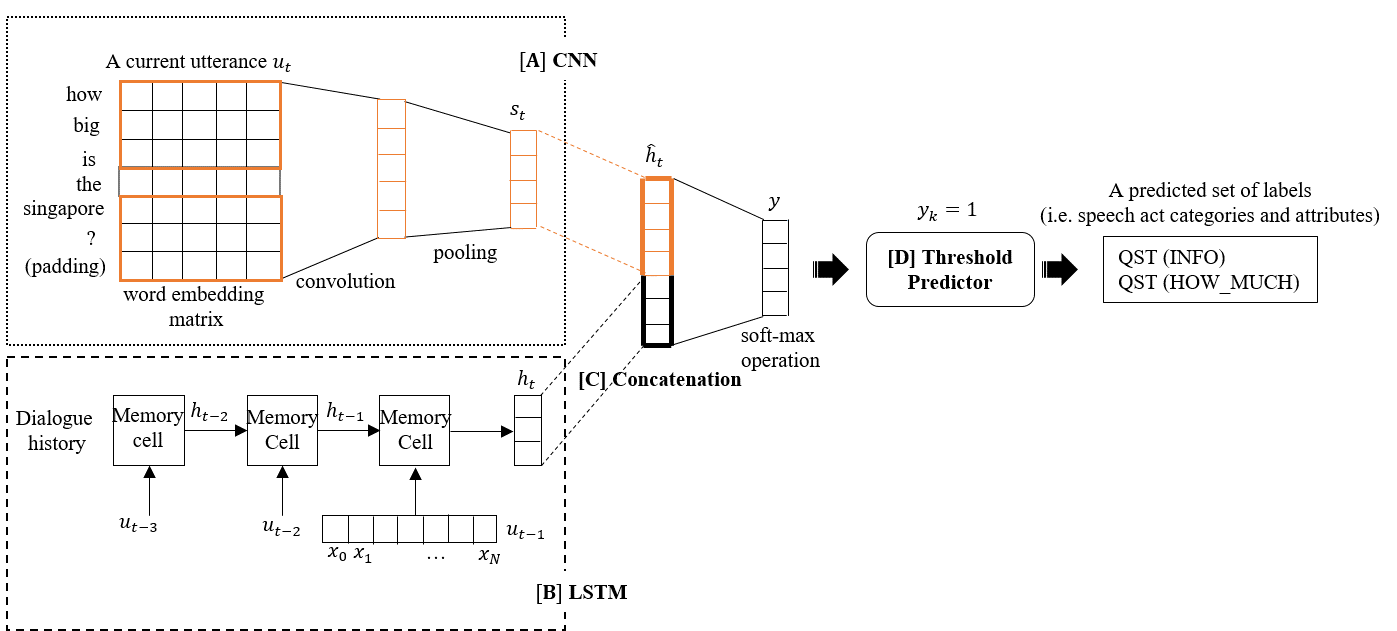 Figure 1. The architecture of our proposed model. Figure 1. The architecture of our proposed model. |
grounded on LSTM. They achieved a higher BLEU score on a translation task from English to French on the WMT-14 dataset, compared to a phrase-based machine translation system[12].
Several researches have been recently conducted by combining CNN and RNN models. Vinyals et al. proposes an conjoined model for image captioning, which encodes image features using deep convolutional networks and automatically generates captions with recurrent networks[13]. Kim proposes a recurrent convolutional network model, in which the penultimate layer of CNN is connected to the recurrent layers of the RNN model in order to track a topic of a dialogue segment in human-human conversations[14]. Unlike the previous CNN-RNN models, another jointed CNN and RNN model is proposed by Barahona et al., where the model is optimized with two distinctive inputs: a current user’ utterance and dialog act-slot pairs of previous system’s utterances [15]. In the task of decoding semantic meaning of spoken languages each input is utilized in sentence representation and context representation, respectively.
3. Model Architecture
In this section, we propose a jointed model which combines Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN) . The overall architecture of our semantic decoder is depiected in Figure 1. Our model consists of three modules: (i) a CNN with multiple filters that encodes semantic meaning of current utterance, output nodes that produces scores for each label, (ii) a RNN with recurrent connections between neurons that store contextual information of dialogues and (iii) a multi-label threshold predictor that generates a reference point using the scores of the labels. The threshold is then used to for the system to decide whether each label is as relevant or irrelevant. Specifically, we newly adopt the RNN to improve the previous semantic decoder of Xu et al. with assistance of contextual information drawn from dialogues so that the disambiguity problem is raveled out.
3.1. CNN Architecture
Coming up with the architecture of CNN [5], which is specifically illustrated in the part [A] of Figure 1, given our CNN classifier is capable of optimizing its parameters with respect to multi-label cross entropy loss function. Formally, let be the k-dimensional word embedding vector corresponding to -th word in a given utterance. An utterance of length are represented as a matrix:
![]() where is the index of dialogue turn and is the concatenation operator. A convolutional operation involves a filter , which is applied to a window of adjacent words to produce a new feature. A feature is generated by applying a hyperbolic tangent function
where is the index of dialogue turn and is the concatenation operator. A convolutional operation involves a filter , which is applied to a window of adjacent words to produce a new feature. A feature is generated by applying a hyperbolic tangent function
![]() where is a bias term. The filter is applied to every possible window of words in the utterance to produce a feature map:
where is a bias term. The filter is applied to every possible window of words in the utterance to produce a feature map:
![]() A max-over-time pooling is then operated to take the maximum value as a representative feature for the filter.
A max-over-time pooling is then operated to take the maximum value as a representative feature for the filter.
Following the same procedure as described above, multiple filters with varying window size are integrally engaged into multiple adjacent features. These features are then concatenated into a fixed-length and ‘top-level’ feature vector which automatically encodes most of representative features from a given utterance at dialogue turn .
3.2. RNN Architecture
Since each utterance is dependent on the previous utterances in a conversation, referring to dialogue context from previous dialogue utterances is essential to wholly understand the meaning of a current utterance. To access to dialogue context, we employ a long short term memory (LSTM). It is much better for preserving information over long periods of time than vanilla RNN due to its ability to deal with vanishing and exploding gradients[16].
To track the dialogue context, two questions must be taken into consideration: (i) to what extent we should track previous utterances as dialogue history and (ii) in which form those utterances are fed into the LSTM as inputs. For length of the dialogue history, we treat it as a free parameter and determine its value empirically. Once the length L is determined, the dialogue history is represented as where is the index of dialogue turn.
As depicted in the part [B] of Figure 2, the structure of LSTM is divided into a memory cell and three gates: a forget gate , an input gate and an output gate . Three kinds of gates functions to decide which amount of information the memory cell should keep or forget at a time step , where l denotes for each word in the utterances given a length L. The input and the output of LSTM are updated as follows:
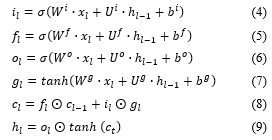 where is the input at the current time step, is the hidden unit at time step , is a bias term, is a logistic sigmoid function and denotes a point-wise multiplication operation. Each word of the utterances in the dialogue history is represented as word embedding vectors and fed into the LSTM sequentially as an input The last hidden unit of LSTM is obtained which encodes the dialogue context information for current utterance .
where is the input at the current time step, is the hidden unit at time step , is a bias term, is a logistic sigmoid function and denotes a point-wise multiplication operation. Each word of the utterances in the dialogue history is represented as word embedding vectors and fed into the LSTM sequentially as an input The last hidden unit of LSTM is obtained which encodes the dialogue context information for current utterance .
3.3. Combining CNN and LSTM
To utilize both the representative feature of current utterance and context information of previous utterances, we concatenate the hidden unit of LSTM to the ‘top-level’ feature vector modeled by the CNN, as illustrated in [C] of Figure 1. Then, the penultimate layer consists of the concatenated vector , which is passed to a fully connected output layer.
![]()
Table 2. Statistics of dstc5 datasets.
M: Number of utterances. L: Size of label set (size/total). C: Average number of labels per utterance.
|
Then the softmax is operated to normalize the output vector to the probability distribution as follows:
![]() where denotes the index of the multi-hot vector , which represents the pairs of speech act attribute and category information of utterance.
where denotes the index of the multi-hot vector , which represents the pairs of speech act attribute and category information of utterance.
3.4. Multi-label Threshold Predictor
The output probability distribution from the softmax layer is used for multi-label prediction, while the proposed model is trained and used in prediction for a given utterance . A relevant label set Y for an utterance is determined by a threshold t as follows:
![]() The threshold learning mechanism used in the literature [17, 18] is adopted in [D] of Figure 1, which models with a linear regression model. The learning procedure is described as follows: For each training example , we set the target threshold value which minimizes the count of misclassified labels as follows:
The threshold learning mechanism used in the literature [17, 18] is adopted in [D] of Figure 1, which models with a linear regression model. The learning procedure is described as follows: For each training example , we set the target threshold value which minimizes the count of misclassified labels as follows:
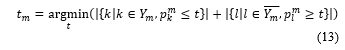 where , is the output probability of relevant label and irrelevant label associated with utterance respectively. The target threshold values is used in learning the of the threshold predictor :
where , is the output probability of relevant label and irrelevant label associated with utterance respectively. The target threshold values is used in learning the of the threshold predictor :
![]() where is the regularization parameter and M is the number of utterances in the train set. At the test time, the learned threshold is used to choose the relevant labels of a test utterance, as illustrated in (14).
where is the regularization parameter and M is the number of utterances in the train set. At the test time, the learned threshold is used to choose the relevant labels of a test utterance, as illustrated in (14).
4. Experimental Setup
In this section we introduce the DSTC5 dataset and describe the different models with their corresponding performances.
4.1. Statistics of DSTC5 Datasets
The summary statistics of the SLU datasets for the both speakers of the DSTC5 after tokenization are given in Table 2. For the case of Guide, one interesting point to note is that the size of sets of labels in the train set is smaller than that in the test set , which means that there is no way for the classifier to learn cases of certain labels assigned to utterances during the training and predict correct speech acts on the test dataset of Guide.
4.2. Hyper-parameters
In our experiments, we use: filter windows of 2, 3, 4 with 200 feature maps for the CNN, dimension of 100 for the hidden unit of LSTM. Those values are chosen by adopting a rough grid search[8]. The model undergoes training through stochastic gradient descent over shuffled mini-batches with Adam optimization algorithm. The model stops the iterant processes of learning by an early stopping mechanism.
As we mentioned in Section 3.2 that the length of dialogue context is treated as a free parameter, the optimal value of is
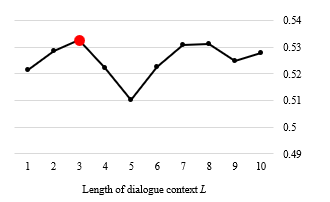 Figure 2. The performance of CNN-LSTM model based on various lengths of dialogue context on Tourist dataset. Figure 2. The performance of CNN-LSTM model based on various lengths of dialogue context on Tourist dataset. |
derived by conducting a grid search, where ranges from 1 to 10 on both Guide and Tourist datasets. Figure 2 and Figure 3 illustrate the performance changes with respect to the length of dialogue context in the Guide and Tourist dataset respectively. It is shown that the optimal length of dialogue context would be L=3 and L=2 for the Tourist and Guide dataset, respectively, for making a dialogue context that improves the classification performance.
4.3. Word Embedding Vectors
GloVe[19] and Word2Vec[20] are the two most popular word embedding algorithms aiming at mapping semantic meaning of words in a geometric space. We initialize our proposed models with two publicly available pre-trained word vectors and both word embedding vectors have dimensionality of 300; GloVe that are trained on 6 billion words from Wikipedia 2014 and Gigaword5[2] and Word2Vec that are trained on 100 billion words from Google News[3]. In the preliminary experiments, it is observed that all the proposed models trained on top of the pre-trained Word2Vec show slightly better performances over those on top of pre-trained GloVe. In this sense only the performances of Word2Vec based models will be presented in this paper.
4.4. Model Variations
We evaluate three models with different architecture:
- CNN (multiclass): the model that predicts only one speech act category and attribute for given a speaker’s
- CNN-LSTM (multiclass): the combined model which exploits dialogue context information from previous speaker’s utterances
- CNN-LSTM (thresholding): the combined model with a threshold predictor that classifies multiple labels of speech act categories and attributes.
4.5. Evaluation Metrics
In the SLU task, a system is required to match relevant speech acts for a given unlabeled utterance spoken by the target role speaker. The following evaluation metrics are used in DSTC5.
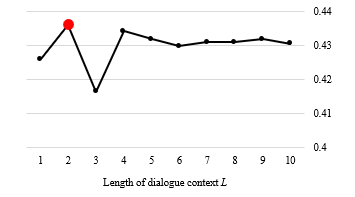 Figure 3. The performance of CNN-LSTM model based on various lengths of dialogue context on Guide dataset. Figure 3. The performance of CNN-LSTM model based on various lengths of dialogue context on Guide dataset. |
- Precision: Fraction of speech act labels that are correctly predicted.
- Recall: Fraction of speech act labels in the gold standard that are correctly predicted.
- F-measure: The harmonic mean between precision and recall.
5. Results
Table 3 and Table 4 summarize the comparative experimental results of our models for classifying speech acts categories and attributes on Guide and Tourist datasets, respectively. On the Tourist dataset, the CNN-LSTM (multi-class) model shows promising results. Note that CNN-LSTM (multi-class) models outperform most of the models submitted in the DSTC5 for both speakers even without utilizing threshold learning mechanism. In terms of the F1-score, the model CNN-LSTM (thresholding) significantly outperforms all the other models on Tourist dataset. For the case of Guide dataset, our model is slightly behind of Team 2’s model, but still highly comparable.
These results suggest that for conducting the SLU task of DSTC5 the CNN is a suitable model to predict and fill the slots of speech act categories and attributes. A threshold predictor enables the CNN models to classify a set of multiple labels on each utterances. It is worthy nothing that our model uses only publicly available word-embedding vectors without having any manually designed features or using delexicalization. Last but the most important thing is the dialogue context information encoded with the LSTM helps to improve the performance of conducting SLU task.
6. Discussion
At this point we circle back to the very beginning in order to understand what limitation had been posed on Xu et al.’s model and how our CNN-RNN model could tackle those issues[4]. The basic ideas of our study start from the properties of utterances. Each utterance is a sub-part of a dialogue and inevitably depends on the previous utterances in the intertwined way. In order to capture the semantic meaning from utterances the semantic
Table 5. An example of test utterances annotated by different models.
|
||||||||||||||||||||||||||||||
Table 3. Comparative results for Tourist dataset
|
Table 4. Comparative results for Guide dataset
|
decoder must be robust enough (i) to detect the semantic meaning from utterances regardless of the specific word order – propositional meaning, and (ii) to understand the intention when a speaker utters them in the middle of dialogues – pragmatic information.
With these preliminaries in place Xu et al.’s model, which is grounded on CNN, overlooked the importance of pragmatic information, although it has specialized capability of extracting out of the necessary information from the current utterance. Our model has concatenated RNN to CNN before the soft-max operation so that it can retrieve the contextual meaning from the previous utterances in the dialogues and build more complete concept structure.
As illustrated in Table 5, our proposed CNN-LSTM model could correctly predict the labels which are supposed to be annotated. Consider the example of an utterance 嗯 ‘uh-huh’. If we only have a look this utterance itself, there is no way to disambiguate the meaning between acknowledge and confirmation. In the case of the example 4, since it has already uttered in the previous turn and both two participants of this dialogue know this fact, the confirmational phrase such as ‘you meant … is it right?’ is omitted to avoid the redundancy. This pragmatic information is stored in the long-term memory and utilized to understand the genuine meaning of corresponding utterance.
7. Conclusion
This paper has extended the work of Xu et al. on the SLU task of DSTC5, and has presented a semantic decoder using deep neural networks. We have compared different models for combining a threshold predictor and long short-term memory. Our concise model proved its efficiency by outperforming the models including the baseline on the DSTC5 and those submitted in the challenge. We observed that understanding the semantic meaning and building a concept structure of a certain utterance is effectively obtained by utilizing both current and previous information. It addresses that the architecture of our concatenated CNN-LSTM model may be applicable to other types of dialogues corpora for achieving SLU.
Acknowledgement
This work was supported by the National Research Council of Science & Technology (NST) grant by the Korea government (MSIP) (No. CRC-15-04-KIST). We sincerely thank two anonymous reviewers and external readers, and the audiences of 2017 Bigcomp conference for their detailed comments. All errors and misrepresentations, if any, are solely ours.
- G. Xu, H. Lee, M. Koo, J. Seo, “Convolutional Neural Network using a Threshold Predictor for Multi-label Speech Act Classification” in Big Data and Smart Computing (BigComp), 2017 IEEE International Conference, pp. 126-130, 2017.
- S. Kim, L. F. D’Haro, R. E. Banchs, J. D. Williams, M. Henderson, K. Yoshino, “The Fifth Dialog State Tracking Challenge” in Proceedings of the 2016 IEEE Workshop on Spoken Language Technology (SLT), pp. 511-517, 2016.
- S. Kim, L. F. D’Haro, R. E. Banchs, J. D. Williams M. Henderson, K. Yoshino, Dialog State Tracking Challenge 5 handbook v3.0, 2016.
- T. Ushio, H. Shi, M. Endo, K. Yamagami, N. Horii, “Recurrent Convolutional Neural Networks for Structured Speech Act Tagging” in Proceedings of the 2016 IEEE Workshop on Spoken Language Technology (SLT), pp. 518-524, 2016.
- Y. Kim, “Convolutional Neural Networks for Sentence Classification” in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1746-1751, 2014.
- P. Wang, J. Xu, B. Xu, C.L. Liu, H. Zhang, F. Wang and H. Hao, “Semantic Clustering and Convolutional Neural Network for Short Text Categorization” in Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics(ACL), pp. 352-357, 2015.
- R. Johnson, and T. Zhang, “Semi-supervised convolutional neural networks for text categorization via region embedding” In Advances in neural information processing systems, pp. 919-927, 2015.
- Y. Zhang, B. C. Wallace, “A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification” in arXiv preprint arXiv:1510.03820, 2016.
- T. Mikolov, M. Karafiát, L. Burget, J. Cernocký and S. Khudanpur, “Recurrent Neural Network based Language Model”, In Proceedings of Interspeech, 2010.
- M. Sundermeyer, R. Schluter, and H. Ney, “LSTM neural networks for language modeling”, In Proceedings of Interspeech, 2010.
- Z. Huang, W. Xu, and K. Yu, “Bidirectional LSTM-CRF models for sequence tagging”, In arXiv preprint arXiv:1508.01991, 2015.
- I. Sutskever, O. Vinyals and Q. V. Le, “Sequence to sequence learning with neural networks”, NIPS Technical report, 2014.
- O. Vinyals, A. Toshev, S. Bengio, D. Erhan, “Show and tell: Lessions learned from the 2015 mscoco image captioning challenge” IEEE transactions on pattern analysis and machine intelligence, 39(4), 652-663, 2017.
- S. Kim, R. E. Banchs, H. Li, “Exploring Convolutional and Recurrent Neural Networks in Sequential Labelling for Dialogue Topic Tracking” in Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL), pp. 963-973, 2016.
- L. M. R. Barahona, M. Gasic, N. Mrkšić, P. H. Su, S. Ultes, T. H. Wen, S. Young, “Exploring Sentence and Context Representations in Deep Neural Models for Spoken Language Understanding” in Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, pp. 258-267, 2016.
- S. Hochreiter, J. Schmidhuber, “Long short-term memory” Neural computation, 9(8), 1735-1780, 1997.
- A. Elisseeff, J. Weston, “A kernel method for multi-labelled classification” Advances in Neural Information Processing Systems, 14, 681-687, 2001.
- J. Nam, J. Kim, E. L. Mencía, I. Gurevych, and J. Furnkranz, “Large-scale multi-label text classification – revisiting neural networks” Machine Learning and Knowledge Discovery in Databases, Springer, 437-452, 2014.
- P. Jeffery, R. Socher, C. D. Manning, “Glove: Global vectors for word representation” in Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP), vol. 14, pp. 1532-1543, 2014.
- T. Mikolov, I. Sutskever, K. Chen, G. Corrado, J. Dean, “Distributed representations of words and phrases and their compositionality” Advances in Neural Information Processing Systems, 3111-3119, 2013.